Spark Read S3
Spark Read S3 - Web the following examples demonstrate basic patterns of accessing data in s3 using spark. Read parquet file from amazon s3. Reading and writing text files from and to amazon s3 We are going to create a corresponding glue data catalog table. Databricks recommends using secret scopes for storing all credentials. Ask question asked 5 years, 3 months ago modified 5 years, 3 months ago viewed 5k times part of aws collective 4 i installed spark via pip install pyspark i'm using following code to create a dataframe from a file on s3. Featuring classes taught by spark. Web in this spark tutorial, you will learn what is apache parquet, it’s advantages and how to read the parquet file from amazon s3 bucket into dataframe and write dataframe in parquet file to amazon s3 bucket with scala example. The examples show the setup steps, application code, and input and output files located in s3. You can grant users, service principals, and groups in your workspace access to read the secret scope.
Spark sql provides spark.read ().text (file_name) to read a file or directory of text files into a spark dataframe, and dataframe.write ().text (path) to write to a text file. Web i have a bunch of files in s3 bucket with this pattern. We are going to create a corresponding glue data catalog table. Databricks recommends using secret scopes for storing all credentials. Web 1 you only need a basepath when you're providing a list of specific files within that path. Web how should i load file on s3 using spark? Featuring classes taught by spark. You can grant users, service principals, and groups in your workspace access to read the secret scope. Myfile_2018_(150).tab i would like to create a single spark dataframe by reading all these files. Web pyspark aws s3 read write operations february 1, 2021 last updated on february 2, 2021 by editorial team cloud computing the objective of this article is to build an understanding of basic read and write operations on amazon web storage service s3.
Using spark.read.csv (path) or spark.read.format (csv).load (path) you can read a csv file from amazon s3 into a spark dataframe, thes method takes a file path to read as an argument. The examples show the setup steps, application code, and input and output files located in s3. Featuring classes taught by spark. Web with amazon emr release 5.17.0 and later, you can use s3 select with spark on amazon emr. Web spark read csv file from s3 into dataframe. Spark sql provides spark.read ().text (file_name) to read a file or directory of text files into a spark dataframe, and dataframe.write ().text (path) to write to a text file. It looks more to be a problem of reading s3. Ask question asked 5 years, 3 months ago modified 5 years, 3 months ago viewed 5k times part of aws collective 4 i installed spark via pip install pyspark i'm using following code to create a dataframe from a file on s3. Web you can set spark properties to configure a aws keys to access s3. Reading and writing text files from and to amazon s3

PySpark Tutorial24 How Spark read and writes the data on AWS S3
S3 select allows applications to retrieve only a subset of data from an object. How do i create this regular expression pattern and read. By default read method considers header as a data record hence it reads. Write dataframe in parquet file to amazon s3. While digging down this issue.

Spark Read Json From Amazon S3 Spark By {Examples}
Web i have a bunch of files in s3 bucket with this pattern. Web with amazon emr release 5.17.0 and later, you can use s3 select with spark on amazon emr. Topics use s3 select with spark to improve query performance use the emrfs s3. Databricks recommends using secret scopes for storing all credentials. When reading a text file, each.
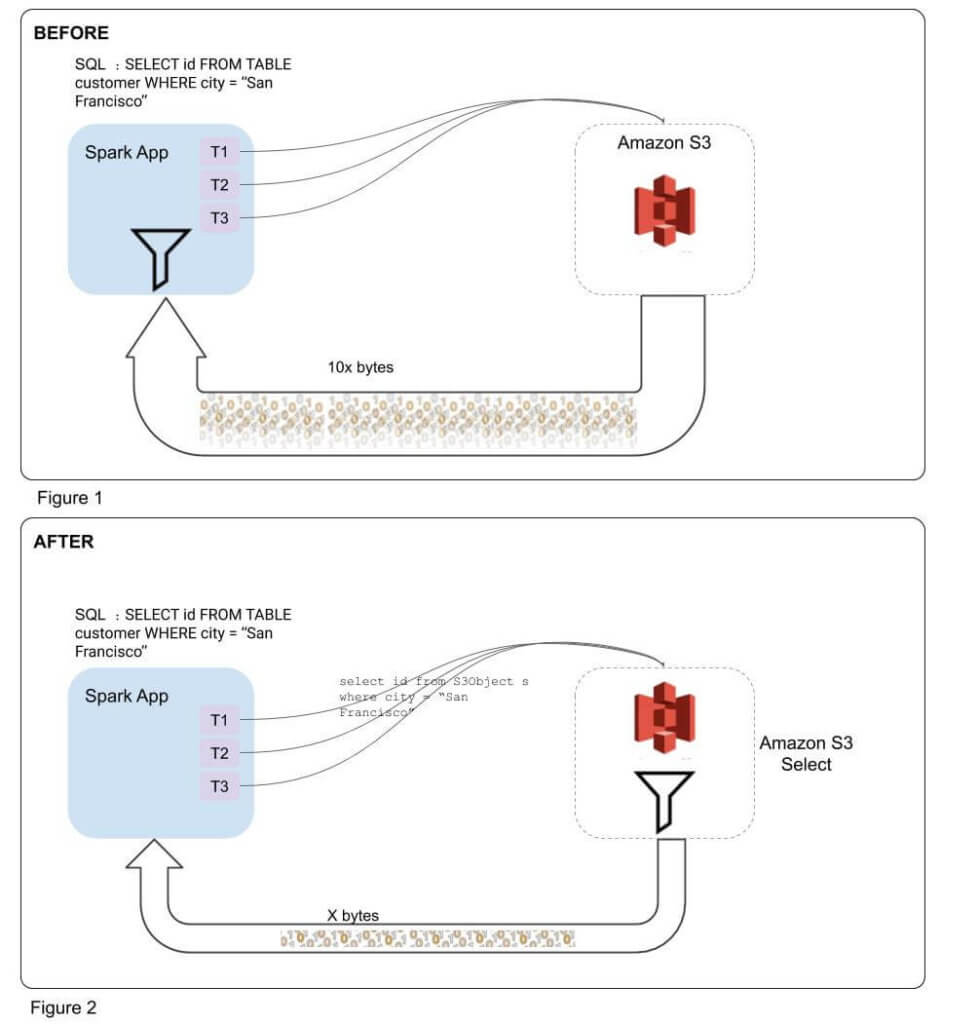
Improving Apache Spark Performance with S3 Select Integration Qubole
Web you can set spark properties to configure a aws keys to access s3. Reading and writing text files from and to amazon s3 Web how should i load file on s3 using spark? Web the following examples demonstrate basic patterns of accessing data in s3 using spark. Web spark read csv file from s3 into dataframe.

Spark Architecture Apache Spark Tutorial LearntoSpark
How do i create this regular expression pattern and read. Web you can set spark properties to configure a aws keys to access s3. This protects the aws key while allowing users to access s3. Ask question asked 5 years, 3 months ago modified 5 years, 3 months ago viewed 5k times part of aws collective 4 i installed spark.

Spark에서 S3 데이터 읽어오기 내가 다시 보려고 만든 블로그
Web i have a bunch of files in s3 bucket with this pattern. It looks more to be a problem of reading s3. We are going to create a corresponding glue data catalog table. @surya shekhar chakraborty answer is what you need. S3 select allows applications to retrieve only a subset of data from an object.

Read and write data in S3 with Spark Gigahex Open Source Data
Web in this spark tutorial, you will learn what is apache parquet, it’s advantages and how to read the parquet file from amazon s3 bucket into dataframe and write dataframe in parquet file to amazon s3 bucket with scala example. Web when spark is running in a cloud infrastructure, the credentials are usually automatically set up. Write dataframe in parquet.

Spark SQL Architecture Sql, Spark, Apache spark
Web pyspark aws s3 read write operations february 1, 2021 last updated on february 2, 2021 by editorial team cloud computing the objective of this article is to build an understanding of basic read and write operations on amazon web storage service s3. Web 1 you only need a basepath when you're providing a list of specific files within that.

spark에서 aws s3 접근하기 MD+R
S3 select allows applications to retrieve only a subset of data from an object. Web with amazon emr release 5.17.0 and later, you can use s3 select with spark on amazon emr. Web in this spark tutorial, you will learn what is apache parquet, it’s advantages and how to read the parquet file from amazon s3 bucket into dataframe and.

One Stop for all Spark Examples — Write & Read CSV file from S3 into
It looks more to be a problem of reading s3. Web spark read csv file from s3 into dataframe. @surya shekhar chakraborty answer is what you need. Spark sql provides spark.read ().text (file_name) to read a file or directory of text files into a spark dataframe, and dataframe.write ().text (path) to write to a text file. Topics use s3 select.

Tecno Spark 3 Pro Review Raising the bar for Affordable midrange
Read parquet file from amazon s3. Reading and writing text files from and to amazon s3 Write dataframe in parquet file to amazon s3. Myfile_2018_(150).tab i would like to create a single spark dataframe by reading all these files. Web with amazon emr release 5.17.0 and later, you can use s3 select with spark on amazon emr.
Myfile_2018_(150).Tab I Would Like To Create A Single Spark Dataframe By Reading All These Files.
When reading a text file, each line. Web with amazon emr release 5.17.0 and later, you can use s3 select with spark on amazon emr. Web in this spark tutorial, you will learn what is apache parquet, it’s advantages and how to read the parquet file from amazon s3 bucket into dataframe and write dataframe in parquet file to amazon s3 bucket with scala example. The examples show the setup steps, application code, and input and output files located in s3.
S3 Select Allows Applications To Retrieve Only A Subset Of Data From An Object.
Databricks recommends using secret scopes for storing all credentials. Featuring classes taught by spark. Write dataframe in parquet file to amazon s3. In this project, we are going to upload a csv file into an s3 bucket either with automated python/shell scripts or manually.
Web How Should I Load File On S3 Using Spark?
Web spark read csv file from s3 into dataframe. By default read method considers header as a data record hence it reads. Web you can set spark properties to configure a aws keys to access s3. @surya shekhar chakraborty answer is what you need.
You Can Grant Users, Service Principals, And Groups In Your Workspace Access To Read The Secret Scope.
Web i have a bunch of files in s3 bucket with this pattern. Web 1 you only need a basepath when you're providing a list of specific files within that path. How do i create this regular expression pattern and read. While digging down this issue.